Semantic understanding as to the goal of Google
One of Google’s most important goals has long been to gain a semantic understanding of search terms and indexed documents to display more relevant search results. A semantic understanding is given if, for example, you clearly understand a (search) question and the terms contained in it, or you can see its meaning. The precise interpretation is often difficult due to the ambiguity of words, previously unknown conditions, unclear wording, proper understanding, etc.

The words used, their order or the thematic, temporal, or geographical context can contribute to a better understanding. With machine learning, such as that used by Rankbrain, Google is now able to recognize terms and entities in search queries and documents quickly and to create new classes of entity types using cluster analyzes automatically. It is also easier to develop new vector spaces for vector space analysis.
This ensures a high level of detail as well as scalability and performance.
Statistics, in combination with machine learning, lead more and more to a semantic interpretation that comes very close to a semantic understanding related to search queries and documents. Google wants to “recreate” a semantic search using statistical methods and machine learning.
Also, a central element of today’s Google search engine, the Knowledge Graph, is based on semantic structures.
Google’s path to semantic search
Google uses the knowledge graph for the semantic search and the Hummingbird update , introduced in 2013 , which started the semantic search. But Google’s interest in developing a semantic search engine goes back over ten years. In 2007, the person responsible for search and user experience, Marissa Mayer, said in an interview with IDG News Service as follows:
“Right now, Google is good with keywords, and that’s a limitation we think the search engine should be able to overcome with time. People should be able to ask questions and we should understand their meaning, or they should be able to talk about things at a conceptual level. We see a lot of concept-based questions – not about what words will appear on the page but more like ‘what is this about?’. A lot of people will turn to things like the semantic Web as a possible answer to that.” Source: http://www.infoworld.com/article/2642023/database/google-wants-your-phonemes.html
In the same interview, Marissa Mayer also made it clear that semantics alone is not the basis for the “perfect search engine.”
“That said, I think the best algorithm for search is a mix of both brute-force computation and sheer comprehensiveness and also the qualitative human component. “
But Google’s focus on semantics can be seen well before 2007. A look at Google’s patent search suggests this. Since 2000, Google has drawn several patents with a view to semantic analyzes of search queries and documents, such as Identification of semantic units from within a search query (2000) or Document ranking based on semantic distance between terms in a text (2004).
It can be assumed that Google has been involved in the development of a search engine with influences from semantics since its founding in 1998.
The first official announcement by Google regarding the use of semantic-like technologies was in 2009. A complete semantic search was not possible due to the lack of scalability. The usability or speed of application would suffer from a semiotic analysis of documents. The output of search results in real-time would not have been possible.
The Knowledge Graph as a semantic database
In 2010, Google bought the Freebase knowledge database, which allows structured information about entities to be stored. I also like to refer to Freebase as a playground, through which Google was able to gain initial experience with structured data. At the same time, Google developed its semantic database with the Knowledge Graph.
In 2012, Google then introduced the Knowledge Graph, which was initially fed by the data collected in Freebase. The open project Freebase was ended in 2014 and transferred to the finished project Wikidata, which is an essential source of information for the Knowledge Graph today.
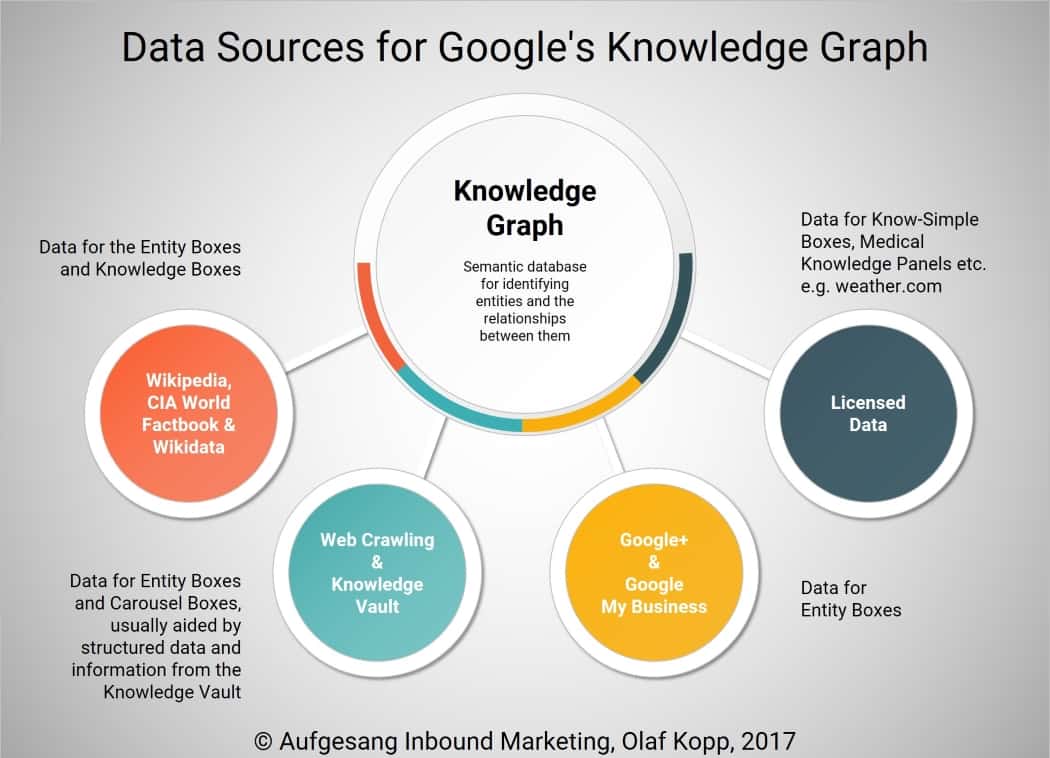
In addition to Wikidata, Google also sources data from Wikipedia, the CIA World Factbook, crawling, and natural language processing of documents, Google My Business, and licensed data.

Data sources for the knowledge graph
Google today – semantic search or just statistical information retrieval?
It is easy to argue about whether Google is a semantic search engine these days.
The way Google outputs results to users these days, it appears that Google already has a semantic understanding of search queries and documents. The idea here is mostly based on statistical methods. Not based on real semantic understanding – but due to grammatical structures in combination with statistics and machine learning, Google comes close to a semantic understanding.
“For instance, we find that useful semantic relationships can be automatically learned from the statistics of search queries and the corresponding results or the accumulated evidence of Web-based text patterns and formatted tables, in both cases without needing any manually annotated data.” Source: The Unreasonable Effectiveness of Data, IEEE Computer Society, 2009
The main problem in the past was the lack of scalability, for example when manually classifying search queries. Ex-Google VP Marissa Mayer in an interview from 2009:
“When people talk about semantic search and the semantic Web, they usually mean something that is very manual, with maps of various associations between words and things like that. We think you can get to a much better level of understanding through pattern-matching data, building large-scale systems. That’s how the brain works. That’s why you have all these fuzzy connections because the brain is constantly processing lots and lots of data all the time… The problem is that language changes. Web pages change. How people express themselves changes. And all those things matter in terms of how well semantic search applies. That’s why it’s better to have an approach that’s based on machine learning, and that changes, iterates, and responds to the data. That’s a more robust approach. That’s not to say that semantic search has no part in the search. It’s just that for us, we prefer to focus on things that can scale. If we could come up with a semantic search solution that could scale, we would be very excited about that. For now, what we’re seeing is that a lot of our methods approximate the intelligence of semantic search but do it through other means.”
Much of what we perceive as a semantic understanding when identifying the meaning of a search query or a document at Google is responsible for statistical methods such as vector space analysis or statistical test methods such as TF-IDF and Natural Language Processing and is therefore not based on real one’s Semantics. But the results come very close to a semantic understanding. The increased use of machine learning, for example, in entity analysis using natural language processing, makes the semantic interpretation of search queries and documents much easier thanks to even more detailed analyzes.
Machine learning or deep learning for scalability
For semantic systems, classes and labels must be predefined to classify data. It is also challenging to identify and create new entities without manual help. For a long time, this was only possible manually or about manually maintained databases such as Wikipedia or Wikidata, which hinders scalability.
The step to a high-performance semantic search engine leads inevitably via machine learning or neural networks.
Google’s involvement in artificial intelligence and machine learning began in 2011 before the launch of “Hummingbird and the Knowledge Graph” with the launch of “Google Brain.”
Google Brain’s goal is to create neural networks. Since then, Google has been working with its deep learning software DistBelief and its successor, Tensor Flow, and the Google Cloud Machine Learning Engine to expand its infrastructure for machine and deep learning.
According to its statements, Google has almost quadrupled its deep learning activities since 2014, as can be seen from the slide in Jeff Dean’s lecture below.
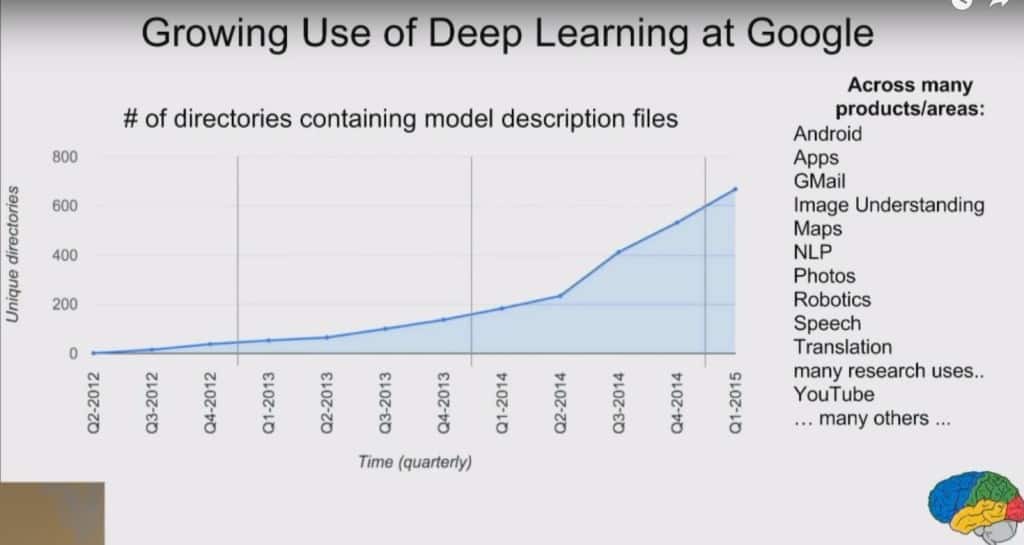
Source: Jeff Dean / Google presentation
So far, machine or deep learning has been used with high probability or according to Google’s statement for the following cases:
- Categorization or identification of search queries according to search intent (informational, transactional, navigational …)
- Classification of content/documents according to the purpose (information, sales, navigation …)
- Discovery, categorization of entities in the knowledge graph
- Text analysis via natural language processing
- Recognition, classification, and interpretation of images
- Recognition, classification, and understanding of language
- Detection, classification, and description of videos
- Translation of languages
The new thing is that Google can now carry out this categorization better and better because it is continually learning and, above all, automated.
Digital gatekeepers like Google need increasingly reliable algorithms to accomplish these tasks autonomously. Self-learning algorithms based on artificial intelligence and machine learning methods will play an increasingly important role here. This is the only way to ensure the relevance of results or expenditure/results in line with expectations – while at the same time ensuring scalability.
With a view to the semantic understanding of search queries and documents, machine learning is essential for performance.
It is, therefore, no coincidence that the three most essential introductions to the Google search Knowledge-Graph, Hummingbird, Rankbrain, and Google’s significantly intensified commitment to machine learning are very close in time over three years.
Conclusion: Google is on the way to semantic understanding
With milestones such as the Knowledge Graph, Hummingbird, and Rankbrain, Google has come to a step closer to the perfect search engine. Statistics, semantic theories, and basic structures, as well as machine learning, play a vital role.
Google wanted to introduce the semantic search with the Knowledge Graph and the Hummingbird algorithm. Today, however, it is becoming clear that the goal of developing a semantic understanding has long failed due to the lack of scalability.
Only in interaction with machine learning systems does the semantic classification of information, documents, and search queries in the broad mass of search queries and reports become practical without having to make significant sacrifices in performance – also thanks to the active help of SEOs and webmasters, the information mark yourself manually.
The ability to make predictions about what a user wants when he enters a previously unknown search term in the search slot has only become possible through machine learning.
The path to the perfect search engine is probably something to go, but the steps there have been significantly larger since 2013. Given the progress Google has made in deep learning in recent years, it can be assumed that semantic understanding will improve exponentially in the future.